
With CUDA 6, we’re introducing one of the most dramatic programming model improvements in the history of the CUDA platform, Unified Memory. In a typical PC or cluster node today, the memories of the CPU and GPU are physically distinct and separated by the PCI-Express bus. Before CUDA 6, that is exactly how the programmer has to view things. Data that is shared between the CPU and GPU must be allocated in both memories, and explicitly copied between them by the program. This adds a lot of complexity to CUDA programs.
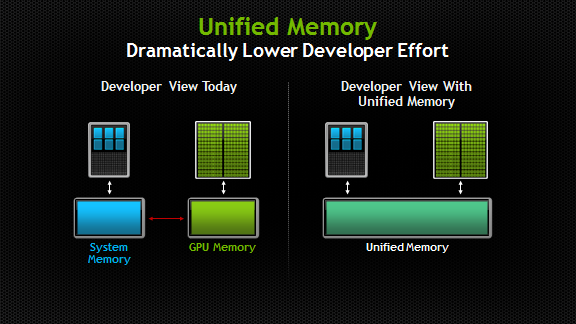
Unified Memory creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The key is that the system automatically migrates data allocated in Unified Memory between host and device so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.
In this post I’ll show you how Unified Memory dramatically simplifies memory management in GPU-accelerated applications. The image below shows a really simple example. Both codes load a file from disk, sort the bytes in it, and then use the sorted data on the CPU, before freeing the memory. The code on the right runs on the GPU using CUDA and Unified Memory. The only differences are that the GPU version launches a kernel (and synchronizes after launching it), and allocates space for the loaded file in Unified Memory using the new API cudaMallocManaged().
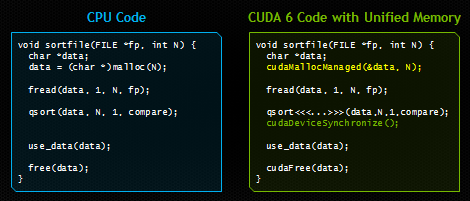
If you have programmed CUDA C/C++ before, you will no doubt be struck by the simplicity of the code on the right. Notice that we allocate memory once, and we have a single pointer to the data that is accessible from both the host and the device. We can read directly into the allocation from a file, and then we can pass the pointer directly to a CUDA kernel that runs on the device. Then, after waiting for the kernel to finish, we can access the data again from the CPU. The CUDA runtime hides all the complexity, automatically migrating data to the place where it is accessed.
What Unified Memory Delivers
There are two main ways that programmers benefit from Unified Memory.
Simpler Programming and Memory Model
Unified Memory lowers the bar of entry to parallel programming on the CUDA platform, by making device memory management an optimization, rather than a requirement. With Unified Memory, now programmers can get straight to developing parallel CUDA kernels without getting bogged down in details of allocating and copying device memory. This will make both learning to program for the CUDA platform and porting existing code to the GPU simpler. But it’s not just for beginners. My examples later in this post show how Unified Memory also makes complex data structures much easier to use with device code, and how powerful it is when combined with C++.
Performance Through Data Locality
By migrating data on demand between the CPU and GPU, Unified Memory can offer the performance of local data on the GPU, while providing the ease of use of globally shared data. The complexity of this functionality is kept under the covers of the CUDA driver and runtime, ensuring that application code is simpler to write. The point of migration is to achieve full bandwidth from each processor; the 250 GB/s of GDDR5 memory is vital to feeding the compute throughput of a Kepler GPU.
An important point is that a carefully tuned CUDA program that uses streams and cudaMemcpyAsync to efficiently overlap execution with data transfers may very well perform better than a CUDA program that only uses Unified Memory. Understandably so: the CUDA runtime never has as much information as the programmer does about where data is needed and when! CUDA programmers still have access to explicit device memory allocation and asynchronous memory copies to optimize data management and CPU-GPU concurrency. Unified Memory is first and foremost a productivity feature that provides a smoother on-ramp to parallel computing, without taking away any of CUDA’s features for power users.
Unified Memory or Unified Virtual Addressing?
CUDA has supported Unified Virtual Addressing (UVA) since CUDA 4, and while Unified Memory depends on UVA, they are not the same thing. UVA provides a single virtual memory address space for all memory in the system, and enables pointers to be accessed from GPU code no matter where in the system they reside, whether its device memory (on the same or a different GPU), host memory, or on-chip shared memory. It also allows cudaMemcpy to be used without specifying where exactly the input and output parameters reside. UVA enables “Zero-Copy” memory, which is pinned host memory accessible by device code directly, over PCI-Express, without a memcpy. Zero-Copy provides some of the convenience of Unified Memory, but none of the performance, because it is always accessed with PCI-Express’s low bandwidth and high latency.
UVA does not automatically migrate data from one physical location to another, like Unified Memory does. Because Unified Memory is able to automatically migrate data at the level of individual pages between host and device memory, it required significant engineering to build, since it requires new functionality in the CUDA runtime, the device driver, and even in the OS kernel. The following examples aim to give you a taste of what this enables.
Example: Eliminate Deep Copies
A key benefit of Unified Memory is simplifying the heterogeneous computing memory model by eliminating the need for deep copies when accessing structured data in GPU kernels. Passing data structures containing pointers from the CPU to the GPU requires doing a “deep copy”, as shown in the image below.
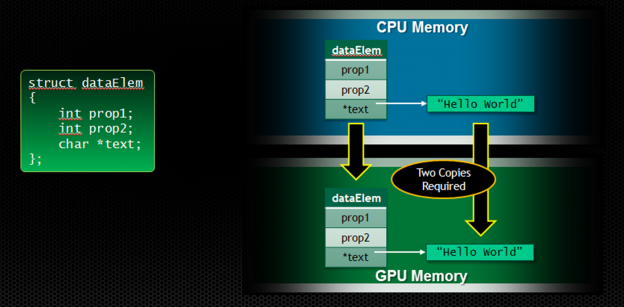
Take for example the following struct dataElem.
To use this structure on the device, we have to copy the struct itself with its data members, and then copy all data that the struct points to, and then update all the pointers in copy of the struct. This results in the following complex code, just to pass a data element to a kernel function.
As you can imagine, the extra host-side code required to share complex data structures between CPU and GPU code has a significant impact on productivity. Allocating our dataElem structure in Unified Memory eliminates all the excess setup code, leaving us with just the kernel launch, which operates on the same pointer as the host code. That’s a big improvement!
But this is not just a big improvement in the complexity of your code. Unified Memory also makes it possible to do things that were just unthinkable before. Let’s look at another example.
Example: CPU/GPU Shared Linked Lists
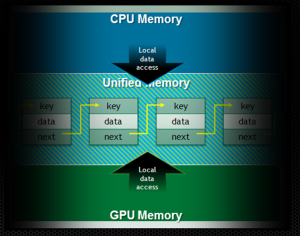
Linked lists are a very common data structure, but because they are essentially nested data structures made up of pointers, passing them between memory spaces is very complex. Without Unified Memory, sharing a linked list between the CPU and the GPU is unmanageable. The only option is to allocate the list in Zero-Copy memory (pinned host memory), which means that GPU accesses are limited to PCI-express performance. By allocating linked list data in Unified Memory, device code can follow pointers normally on the GPU with the full performance of device memory. The program can maintain a single linked list, and list elements can be added and removed from either the host or the device.
Porting code with existing complex data structures to the GPU used to be a daunting exercise, but Unified Memory makes this so much easier. I expect Unified Memory to bring a huge productivity boost to CUDA programmers.
Unified Memory with C++
Unified memory really shines with C++ data structures. C++ simplifies the deep copy problem by using classes with copy constructors. A copy constructor is a function that knows how to create an object of a class, allocate space for its members, and copy their values from another object. C++ also allows the new and delete memory management operators to be overloaded. This means that we can create a base class, which we’ll call Managed, which uses cudaMallocManaged() inside the overloaded new operator, as in the following code.
We can then have our String class inherit from the Managed class, and implement a copy constructor that allocates Unified Memory for a copied string.
Likewise, we make our dataElem class inherit Managed.
With these changes, the C++ classes allocate their storage in Unified Memory, and deep copies are handled automatically. We can allocate a dataElem in Unified Memory just like any C++ object.
Note that You need to make sure that every class in the tree inherits from Managed, otherwise you have a hole in your memory map. In effect, everything that you might need to share between the CPU and GPU should inherit Managed. You could overload new and delete globally if you prefer to simply use Unified Memory for everything, but this only makes sense if you have no CPU-only data because otherwise data will migrate unnecessarily.
Now we have a choice when we pass an object to a kernel function; as is normal in C++, we can pass by value or pass by reference, as shown in the following example code.
Thanks to Unified Memory, the deep copies, pass by value and pass by reference all just work. This provides tremendous value in running C++ code on the GPU.
A Bright Future for Unified Memory
One of the most exciting things about Unified Memory in CUDA 6 is that it is just the beginning. We have a long roadmap of improvements and features planned around Unified Memory. Our first release is aimed at making CUDA programming easier, especially for beginners. Starting with CUDA 6, cudaMemcpy() is no longer a requirement. By using cudaMallocManaged(), you have a single pointer to data, and you can share complex C/C++ data structures between the CPU and GPU. This makes it much easier to write CUDA programs, because you can go straight to writing kernels, rather than writing a lot of data management code and maintaining duplicate host and device copies of all data. You are still free to use cudaMemcpy() (and particularly cudaMemcpyAsync()) for performance, but rather than a requirement, it is now an optimization.
Future releases of CUDA are likely to increase the performance of applications that use Unified Memory, by adding data prefetching and migration hints. We will also be adding support for more operating systems. Our next-generation GPU architecture will bring a number of hardware improvements to further increase performance and flexibility.
Find Out More
In CUDA 6, Unified Memory is supported starting with the Kepler GPU architecture (Compute Capability 3.0 or higher), on 64-bit Windows 7, 8, and Linux operating systems (Kernel 2.6.18+).To get early access to Unified Memory in CUDA 6, become a CUDA Registered Developer to receive notification when the CUDA 6 Toolkit Release Candidate is available. If you are attending Supercomputing 2013 in Denver this week, come to the NVIDIA Booth #613 and check out the GPU Technology Theatre to see one of my presentations about CUDA 6 and Unified Memory (Tuesday at 1:00 pm MTN, Wednesday at 11:30 am, or Thursday at 1:30 pm. Schedule here).

 Copyright © 2014. GPIUTMD - Graphic Processor Units for Many-particle Dynamics
Copyright © 2014. GPIUTMD - Graphic Processor Units for Many-particle Dynamics